Swurg is a Burp Extender designed to make it easy to parse swagger documentation and create baseline requests. This is a function that penetration testers need if they are being asked to test an API.
Our ideal pre-requisites would be:
A Postman collection with environments configured and ready to go valid baseline requests. Ideally setup with any necessary pre or post request scripts to ensure that authentication tokens are updated where necessary.
— Every penetration tester
Not everyone works that way so we often have to fall back to a Swagger JSON file. In the worst cases we get a PDF file with 100s of pages of exposition and from here we are punching up hill to even say hello to the target. That is a cost to the project and isn’t a great experience for your customers either.
If you are reading this post and you are somehow in charge of how you distribute API details to your customers. Then I implore you to NOT rely on that massive PDF approach. This is for your sanity as much as for customers. Shorten your guides to explain how to authenticate and what API calls are required in a sequence to achieve a specific workflow. Then by providing living breathing documentation which is generated from your code you will rarely have to update the PDF. With the bonus that your documentation will be easier to interact with and accurate to the version of the code it was compiled against.
Anyway you have come here to learn how to setup and start using Swurg.
A shout out and thank you to the creator Alexandre Teyar who saw a problem and fixed it. Not all heroes wear capes.
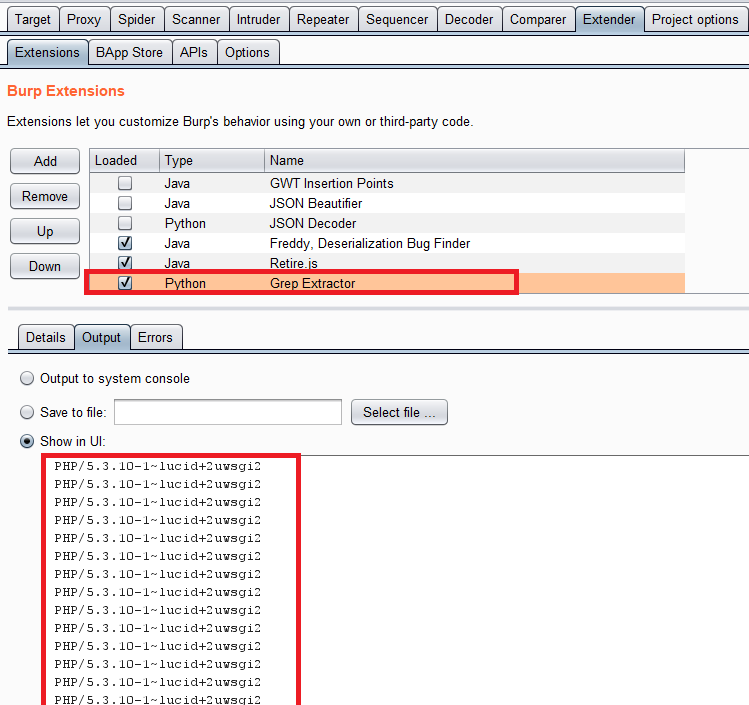
This extender is now in the Burp app store under the name “OpenAPI Parser” so you can install it the easy way.
But if you want to make any changes to the Extender or others in general then the next few sections will be useful.
Check that you have Java in your Path
Open a command prompt and type:
java --version
If you get a warning that the command cannot be located then you need to:
- Ensure that you have a version of the JDK installed.
- That the path to the /bin folder for that JDK is in the environment’s PATH variable.
Note: after you have added something to the PATH variable you need to load a new command prompt for the change to take effect. There is probably a neat way to bring altered environment variables into the current cmd.exe session but honestly? I have so rarely needed to set environment variables on windows I would not retain the command in memory anyway so a restart suits me.
Installing Git Bash
I already had Git Bash installed but you might need it:
This has a binary installer which works fine and I have nothing more to add your honour.
Installing Gradle on Windows 10
There is a guide (link below) but it missed a few beats for Windows 10:
Step 1 download the latest binary only release from here:
There is no installer for the binary release so you have to do things manually. You will have a zip file. It tells you to extract to “c:\gradle”. Installing binaries in the root of c:\ has historically been exploitable in Windows leading to local privilege escalations. So I get nervous when I see this in the installation guide!
Usually “C:\Program Files\gradle” would be the location for an application to be installed. In Windows 10 you are going to need admin privileges to write to either of these locations. It is generally assumed that basically all developers have this but that is often not the case.
Based on the installation steps you should be able to unzip anywhere you have write access such as “C:\Users\USERNAME\Desktop” or other location.
Having extracted the Zip you should add some environment variables:
- GRADLE_HOME – set this to point to the folder you extracted. The location should be the parent folder of “/bin”.
- JAVA_HOME – set this to point to the root folder of a JDK install. This is also going to be the parent folder of “/bin”.
Finally you need to add this this to your PATH variable:
%GRADLE_HOME%/bin
If you ever upgrade to a newer version of gradle (and from the installer I expect there is not an automated update process) then you unzip the new version and change where GRADLE_HOME points to and your updated version will work.
Open yourself a new cmd prompt to ensure the env variables are applied. Type “gradle” and get your rewards:
Now lets get back to Swurg!
Building Swurg
The repository has excellent install instructions here:
But to tie it all together in my single post I’ll replicate what I needed to do.
I used git bash to clone the repository down and then gradle to build the jar:
git clone https://github.com/AresS31/swurg
cd swurg
gradle fatJar
That worked an absolute treat:
That process completes and leaves you a fresh new jar file in the “\build\libs” folder:
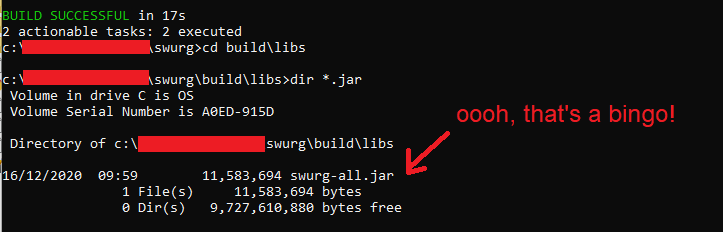
Installing Swurg in Burp
Use the “Extender” -> “Add” functionality to select the “swurg-all.jar”:
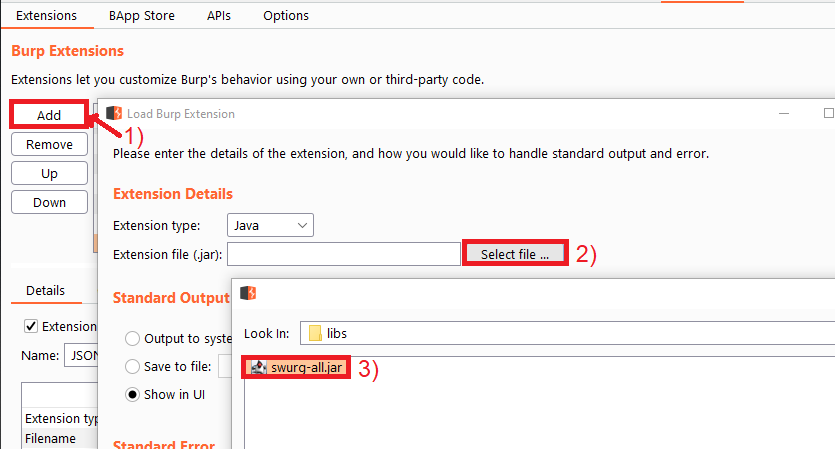
Using Swurg
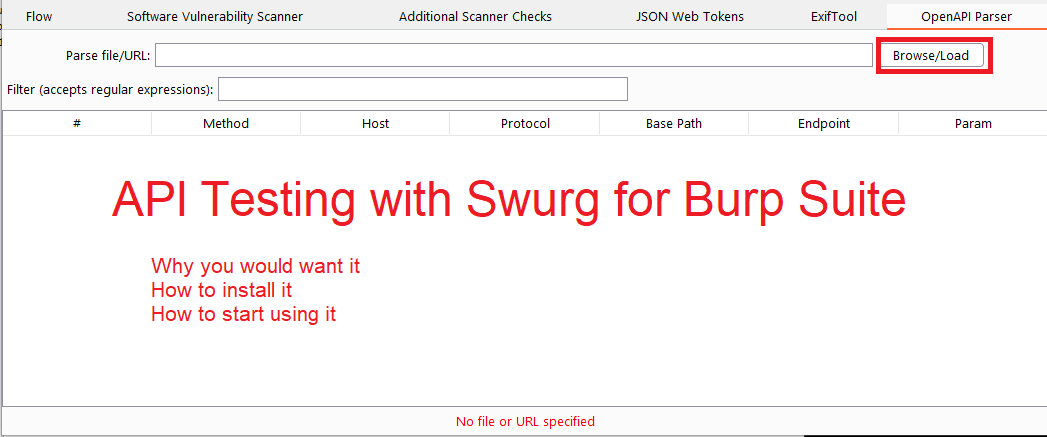
You should now have a new tab and the opportunity to load a swagger file:
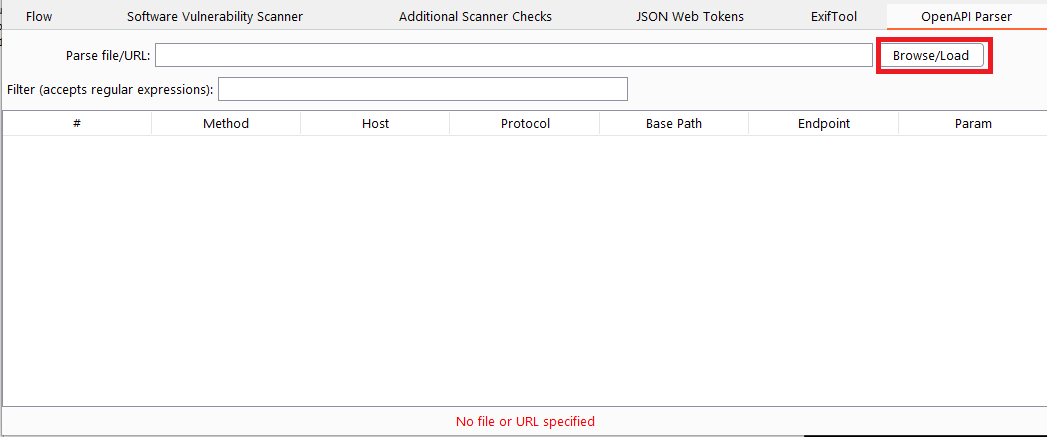
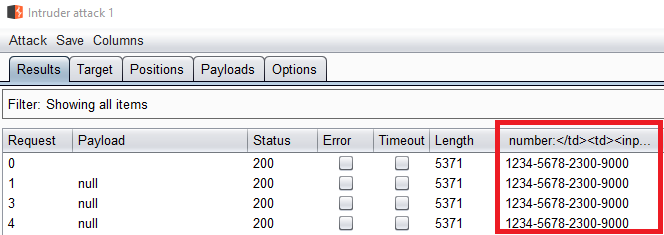
If you load a valid swagger file this will create a full list of endpoints that you can explore.
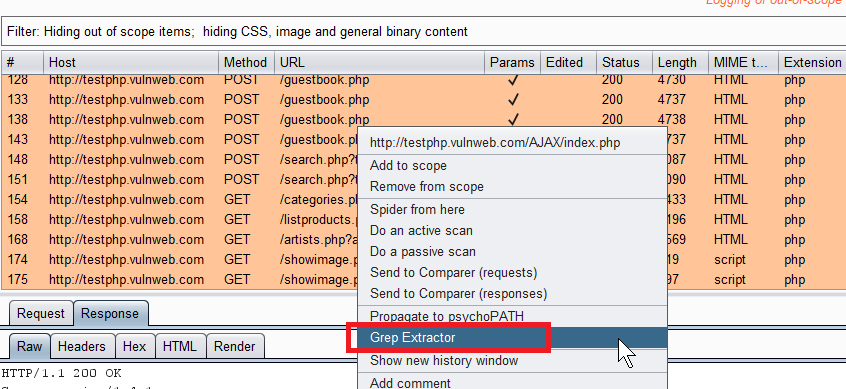
Right click on an endpoint and you have an excellent place to start launching things from:
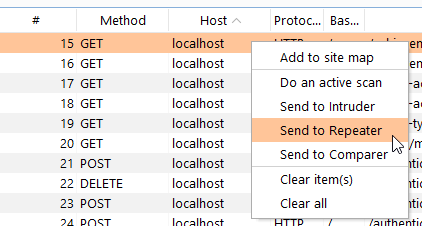
That is definitely enough to get going with. In my case I had replaced my target host with localhost to keep things anonymous as to what I was testing.
This worked well for me and was probably worth the setup. I prefer this to using Swagger-EZ which I have been using in the past.
If we are honest what we all want is a properly configured Postman collection which allows you to have fully configurable environment variables and run pre/post scripts for things such as taking the current Bearer token automatically into all subsequent requests.
In lieu of that this is a reasonable starting point which is embedded where you want it right into Burp suite. If I was to make any changes to the Extender I would probably want an option to globally set the host name and base folder locations. One of those “If I ever get the time” projects.
Hope this helps someone.